Datapipe
Real-time, incremental ETL library for Python with record-level dependency tracking
Real-time, incremental ETL library for Python with record-level dependency tracking
Datapipe processes only new or modified data, significantly reducing computation time and resource usage.
The library supports real-time data extraction, transformation, and loading.
Automatic tracking of data dependencies and processing states.
Seamlessly integrates with Python applications, offering a Pythonic way to describe data pipelines.
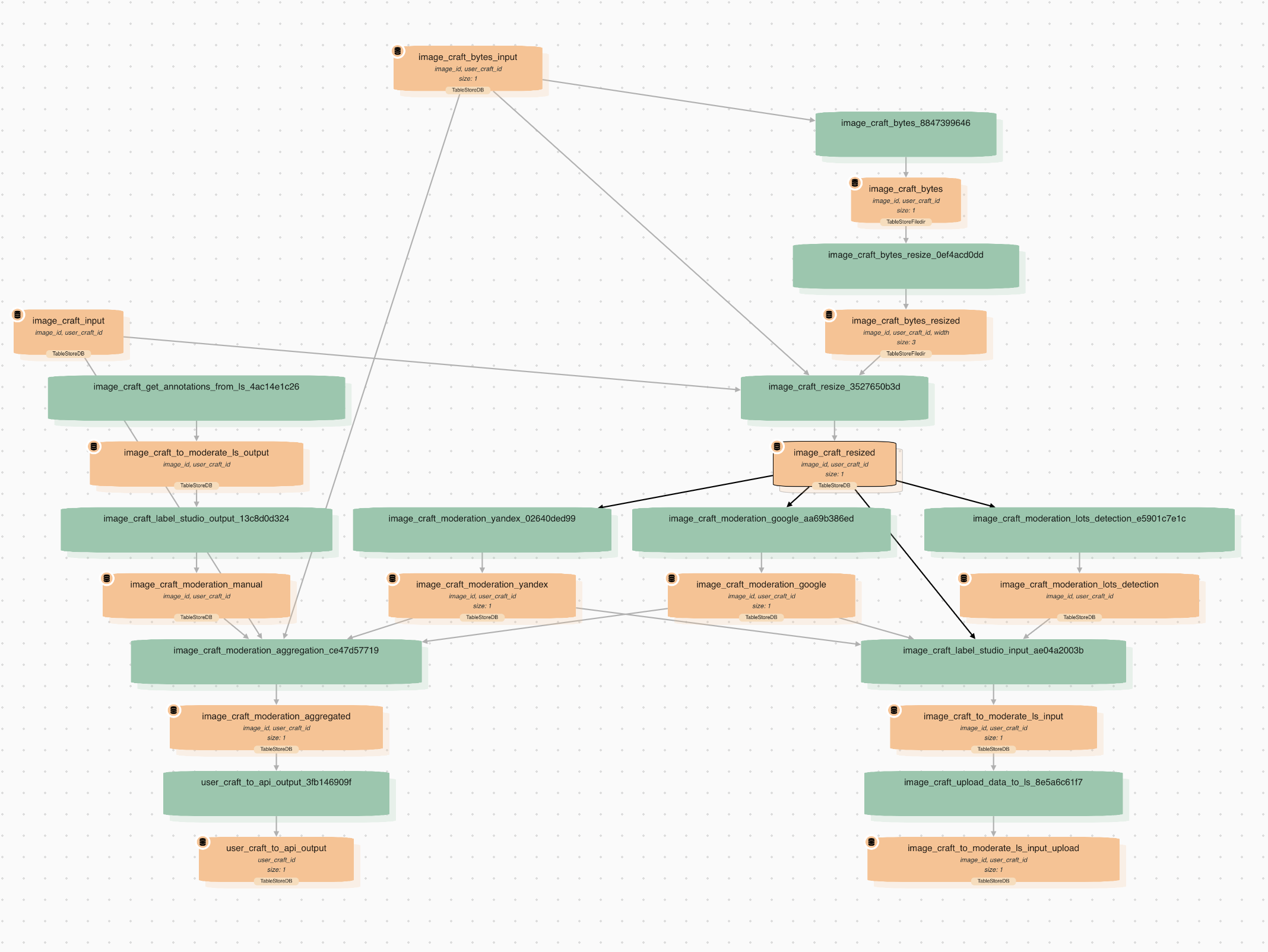
Datapipe lets you build complex pipelines and track data dependencies. We can trace how a specific data row evolves from the first to the last transformation.
.png)


Imagine you have an ML pipeline with detection and classification steps. As development progresses, you eventually have 100 detection and 100 classification models to apply to a dataset of 1000 pictures. If you run the entire processing for the first time, it would take a few days. However, if you add more images or models later, only the new data will be incrementally recalculated, eliminating the need to write any additional code.
The integration of human input into ML models through Datapipe is extremely efficient. Annotators' input is seamlessly incorporated into the pipeline, enabling real-time retraining of all models. This allows annotators to observe immediate improvements, thus accelerating their work.
The ability to run pipelines in different modes – full or partial calculation – is invaluable. For real-time predictions and quick integration of new data, you can run the pipeline with a subset of data, ensuring agility and efficiency.
Datapipe allows room for errors. If you miss a case in a transformation and it crashes, you can quickly fix it and resume the calculation without having to start all over again.
When you delete something in Datapipe, the cleanup is automatic and thorough. It saves a lot of time and ensures data integrity.

Andrey is the founder of Epoch8.co – agency for AI/ML projects. Developed Datapipe to speed up client ML projects

A pioneering early adopter of Datapipe. He has developed over 1000 pipeline nodes across numerous client projects

Initially Andrey worked for our first client to implement Datapipe. He fixed numerous issues in the Datapipe core and eventually joined our team.

Had to learn Python coding to work on Datapipe.
For the detailed documentation and usage cases.
Your support request has been successfully submitted. We'll be in touch soon to help you navigate your Datapipe journey.